

At Standard Metrics — the portfolio management platform for VCs — we believe that AI can be massively enabling in automating repetitive tasks, analyzing vast amounts of data quickly, and improving customer experiences. As Large Language Models (LLMs) like Open AI’s GPT-4 or Anthropic’s Claude have expanded their capabilities and accuracy, we have been increasingly focused on using AI to build better, more efficient products and processes — most notably by increasing our output of documents parsed by AI as we bring on more customers.
In our initial product experiments, we tried using LLMs to parse large documents for complicated tasks without implementing any segmentation by document type. However, extremely high data fidelity is critical for our customers to power processes like LP reporting, valuations, and audits, and we needed to identify mechanisms to further increase parsing accuracy. We’ve been researching ways to improve the accuracy of our AI-powered processes and landed on two critical steps: limiting context (e.g. the amount of information the LLM has to process) and simplifying jobs (e.g. what the LLM has to do to that information) for better in-context learning.
Here, we’ll discuss how these models think, present two different research findings on context length and job complexity that inspired us, review the steps we took to improve our AI-powered processes with this research in mind, and talk through what we’re focused on next. Our hope is that it can be helpful to others concerned with implementing AI best practices into their engineering and product workflows.
How models think
LLMs are only as good as the data they are provided. Models are initially trained on a set of data in order to, essentially, predict the next word (or two) in a sentence. They use massive volumes of training data along with the user-provided prompt to influence their prediction of the next word in the sentence you’re writing or in the question you’re asking. Some predictions have large amounts of data that can make a model extremely confident what the right answer will be.
For example, if we ask someone to pick the next word in this sentence: “Roses are Red, Violets are ___” every single English speaker on the planet will fill in the word “blue”. Models have consumed all of the same information we have (and much more), which will lead them to confidently answer the same: Blue.

This is an example of a model relying solely on its training data; there is sufficient information about this topic baked into the model that it is capable of answering this question.
Defining in-context learning
But while models are initially trained on a set of data, models can also consume the prompts you provide and use that information to support their answers. This process is often described as in-context learning or prompt engineering and is an adaptable way for LLMs to perform tasks without excessive extra training.
For example, here we tell the model that our favorite number is 17. We then ask the model what our favorite number is.

The model gets this right with no issues. We’ve provided new context — our favorite number — and given the model a very simple prompt for interfacing with this context. As a result, the model correctly used the context from our prompt in guessing the right words for its output.
So what’s the problem?
When we integrate AI-powered processes into product workflows, however, we’re often giving LLMs significantly more context (for example, a hundred page document of favorite numbers) and significantly more complicated tasks (for example, “match a name and address to each of those favorite numbers”) than the example above. These context-heavy, complicated tasks can lead to errors, which impact every company leveraging these new AI models.
Context length learnings
Given this, we decided to explore reducing the amount of context that we were feeding our LLMs, researching how different context lengths affected accuracy. In a recent study, researchers measured the accuracy of recall from models with different token context lengths. A larger primer on what constitutes a token can be found here. (The TLDR? A token is a sequence of textual characters that equals about 3/4ths a word.)
The chart below shows that models perform well at their task with high accuracy with less than 4,000 tokens of context. But as the context gets larger, models start to struggle with performance.
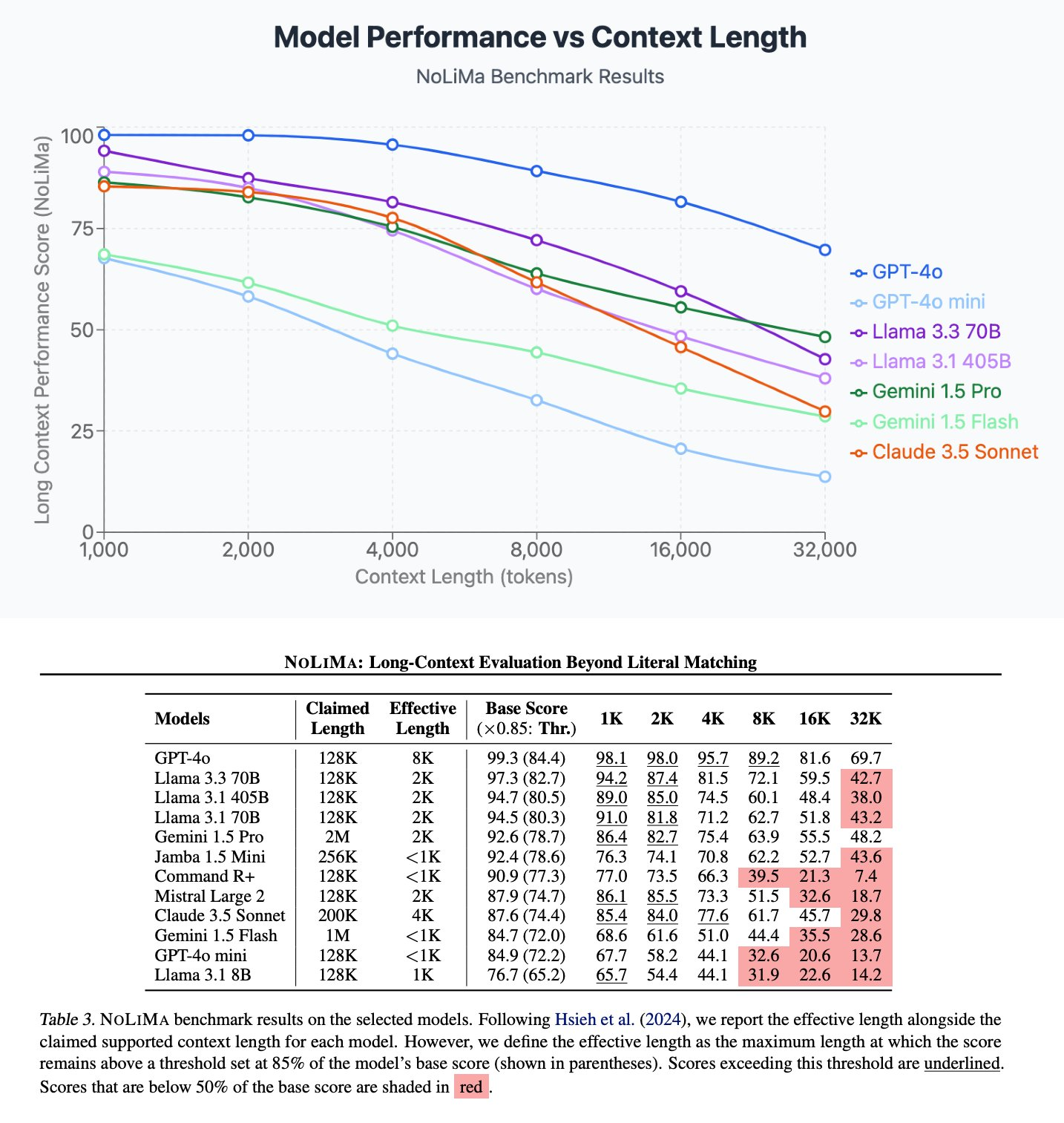
This is because as the amount of context that the LLM needs to process increases, the job asked of it in one go becomes more varied and, thus, performance starts to degrade. It becomes difficult for the LLM to predict what the next word should be, given the larger context it must sift through.
Prompt complexity problem
We also wanted to understand the types of prompts that led to performance degradation (and avoid asking them in the future). One blog post from Oscar Health was particularly helpful. In it, the Oscar Health team asked an LLM to get the color of a large list of objects like a life jacket, cranberry, or blackberry. The match rate for this was very high, nearing 100%.
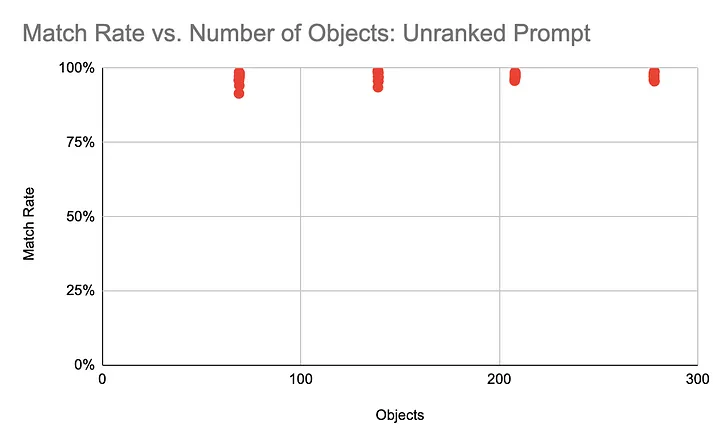
Next, the LLM was asked to:
- Classify colors.
- Rank the colors in order of frequency.
- List all of the objects of the most frequently occurring color first.
- List objects with like colors together.
It’s unsurprising that the LLM scored less accurately on the task as a whole, given the additional complexity. However, what is surprising is that the LLM’s performance on the task of getting the color right within this set of directions – something it did easily with a less complex task — also significantly degraded. The plot below shows the % of colors that the LLM got correct.
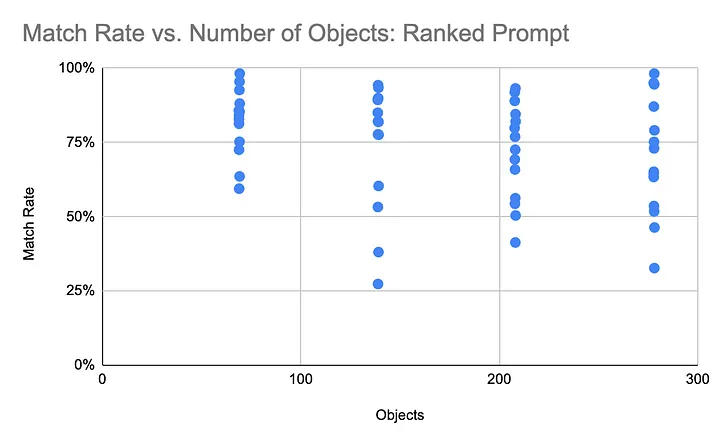
Given the additional instructions, the LLM’s accuracy degraded in both its original task and the task as a whole.
How did we implement this research?
From our research, we understood that with a little context and simple prompts, in-context training can be accurate and reliable. The clearer the context and the prompt, the more accurate the LLM is. With this research in mind, we worked to decrease the amount of information our LLMs had to process as well as the complexity of the jobs we were asking it to complete.
For example, our previous process for AI document parsing — where we pulled startups’ financial data into our platform — was a “single-step parsing” process that applied the same prompt and pre-processing steps for all document categories, with all internal “steps” of the process in the same order. On top of uploading large document dumps (e.g. excessive context), this process also led to non-specific, complicated prompts that weren’t segmented by document types.
Now, we are splitting processing to a “multi-step parsing” workflow where we pre-classify what type of document the LLM is parsing (balance sheets vs. income statements, for example) in order to give different documents more specific and simpler prompts.
What’s next?
Broadly, Standard Metrics is aiming to increase our use of AI with more customer-facing AI analysis features, more documents parsed by AI, AI data summarization, and much more while maintaining extremely high accuracy rates. We’ll be continuously iterating with the principles of shorter context and less complex tasks in mind as we leverage AI in new ways on our platform.
Let us know if you’d like to learn more!
Automate your portfolio reporting
Find out how you can:
- Collect a higher volume of accurate data
- Analyze a robust, auditable data set
- Deliver insights that drive fund performance
